As a founder in the B2B SaaS world, it's easy to fall into the trap of thinking we know our users. We look at the job titles they give us during sign-up, maybe "Product Manager", "Engineer", or "Analyst", and build our entire onboarding and customer success strategy around those labels.
Or we set up great-looking funnels in our product analytics tools, only to find out too late that they represent our interpretations of our customers’ needs, not the reality, the jobs that the customers really want to do.
But we've all seen the reality: the user who calls themselves a "Product Manager" might only ever view dashboards. The "Engineer" might spend all their time in the team collaboration features. Job titles are often a poor reflection of what someone actually does inside a product. They are a guess, an assumption. And in a product-led world, assumptions are expensive.
What if you could bypass the labels and understand your users based on their actual behavior? What if you could automatically discover the natural roles that exist within your user base, just by analyzing the data you already have?
This is a powerful, data-driven process that uses AI to find these user personas automatically. It’s less about asking "Who are you?" and more about observing "What are you trying to accomplish?"
Here’s the modern data workflow for discovering user roles with AI:
- Tapping into Your Product's Data Stream: Collect raw event data from CDPs or product analytics tools into a central data warehouse.
- Finding the "Jobs-to-be-Done" with AI: Use Sentence Transformers and HDBSCAN clustering to identify core user "jobs" from session data, labeled by LLMs.
- Building a Behavioral Fingerprint: Create a unique profile for each user showing their time spent on different "jobs."
- Finding Your User Tribes: Group users with similar behavioral fingerprints using K-Means clustering to discover natural roles.
- Bringing the Data to Life with Personas & Avatars: Generate complete personas (description, JTBD, behaviors, pain points) and visual avatars using AI.
From Clicks to Personas: The Modern Data Workflow
The approach is like being a behavioral scientist for your own product. We take the raw stream of user activity, find the meaningful patterns within it, and then use AI to translate those patterns into human stories. It all starts with getting your data in order.
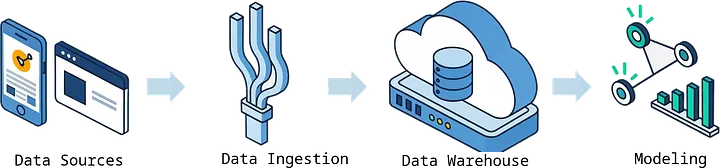
Step 1: Tapping into Your Product's Data Stream
Every action a user takes in your app generates an event. This stream of clicks, views, and creations is the raw material for our analysis. Thankfully, most modern SaaS companies are already collecting this data.
- Event Sources: Your data might be flowing from a Customer Data Platform (CDP) like Segment or Rudderstack, which acts as a central hub. Or it might be coming directly from product analytics tools like Amplitude, Mixpanel, or Posthog.
- Centralizing for Analysis: To do this kind of analysis, you need the raw data in one place. The best practice is to pipe these event streams into a central data warehouse like BigQuery, or Snowflake. Tools like Airbyte or Fivetran make this data ingestion (the ELT part) straightforward.
- Cleaning and Modeling: Once the data is in your warehouse, you can use a tool like dbt to clean and transform it, grouping individual events into user sessions. A session is basically a single "work period" where a user is actively engaged, forming the basic unit for our behavioral analysis.
Step 2: Finding the "Jobs-to-be-Done" with AI
With clean session data, we can get to the interesting part. Instead of just counting clicks, we use AI to understand the meaning behind a user's session. A sequence like "create_project -> configure_settings -> invite_user" isn't just three events; it represents a core "job," such as "Setting up a new collaborative project."
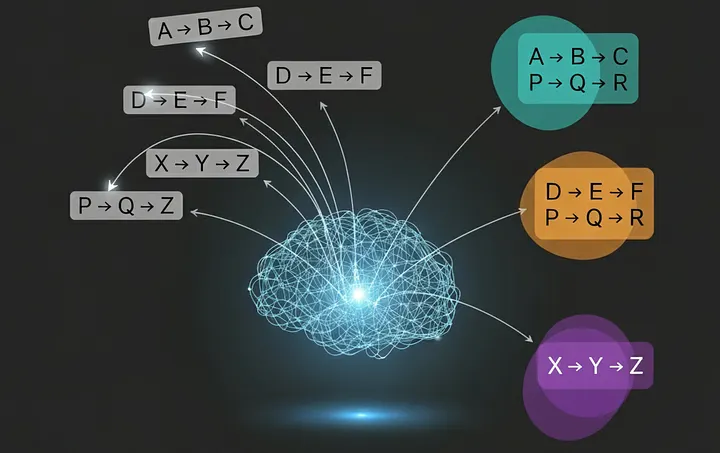
To do this, we use a couple of powerful algorithms:
- Sentence Transformers for Embeddings: We treat each session string as a sentence. A Sentence Transformer model reads this sequence and converts it into a numerical "fingerprint" (called an embedding). The magic here is that sessions with similar user intent, even if the clicks are slightly different, will have mathematically similar fingerprints.
- HDBSCAN for Clustering: To find the natural groups of "jobs" within all these session fingerprints, we use an algorithm called HDBSCAN. It's particularly good for this task because it identifies dense clusters of similar activities and intelligently marks unique, one-off sessions as noise. This keeps our final job categories clean and meaningful.
Finally, we use a large language model like Google's Gemini to give each of these machine-generated clusters a human-readable name, turning abstract groups into concrete jobs like "Project Setup" or "Team Collaboration."
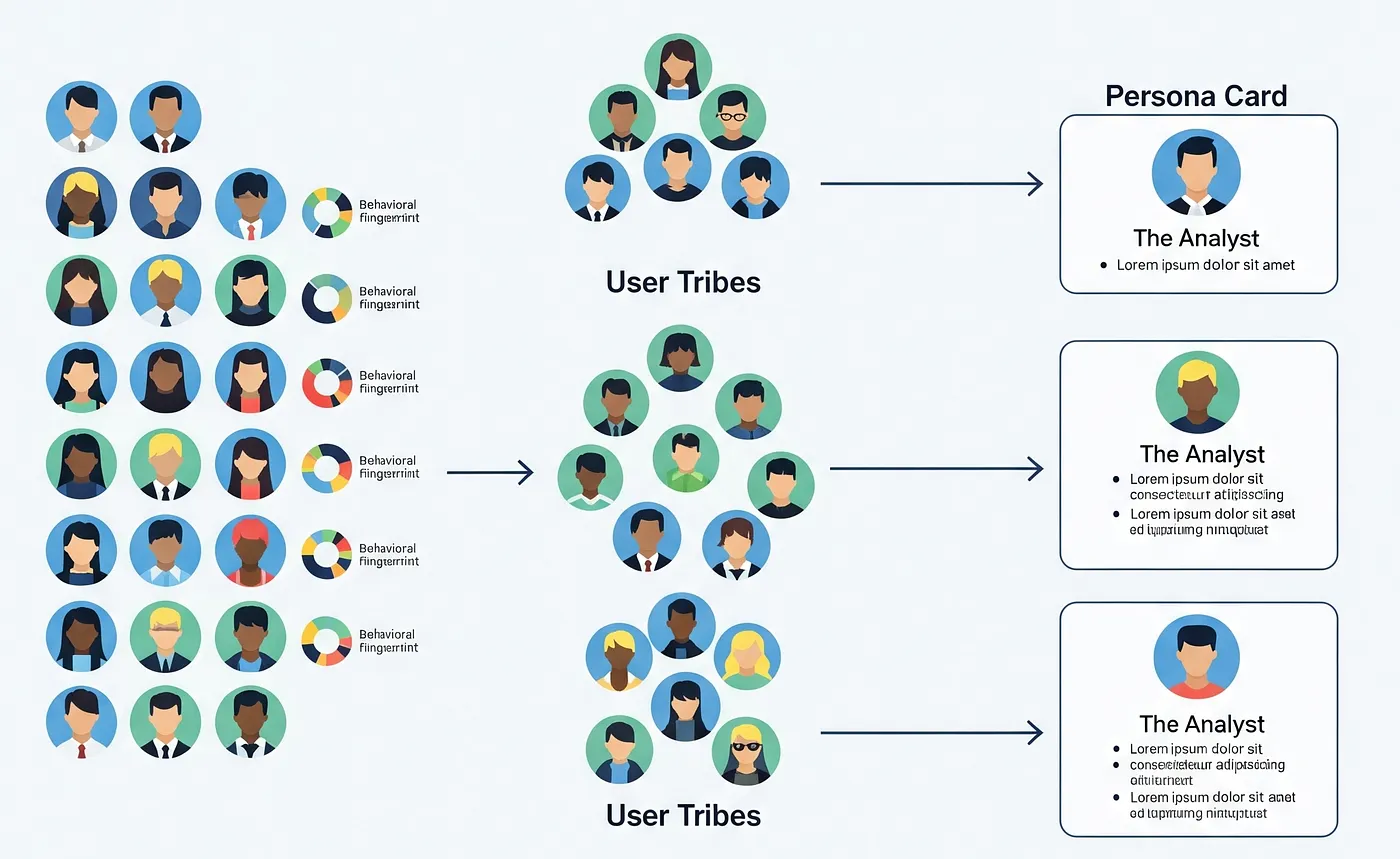
Step 3: Building a Behavioral Fingerprint
With these "jobs" identified, we can now create a unique behavioral fingerprint for each user. This profile shows what percentage of their time is spent on each job. For example:
- User A's Fingerprint: 70% Team Collaboration, 20% Data Analysis, 10% Setup.
- User B's Fingerprint: 10% Team Collaboration, 80% Data Analysis, 10% Setup.
These profiles are the behavioral DNA we'll use to discover our final roles.
Step 4: Finding Your User Tribes
Now, we group users with similar fingerprints. By clustering these profiles, we can find the natural "tribes" within our user base. These clusters aren't based on job titles, but on shared patterns of how they use the product.
- K-Means Clustering: For this segmentation task, we use K-Means clustering. It’s a workhorse algorithm that’s great for partitioning user profiles into a specific number of distinct "role" groups.
- The Elbow Method: To avoid just guessing the number of roles, we use the Elbow Method. By running K-Means with different numbers of clusters and plotting the results, we can identify the "elbow point" where adding more roles stops providing much new information. It's a data-driven way to find the right balance.
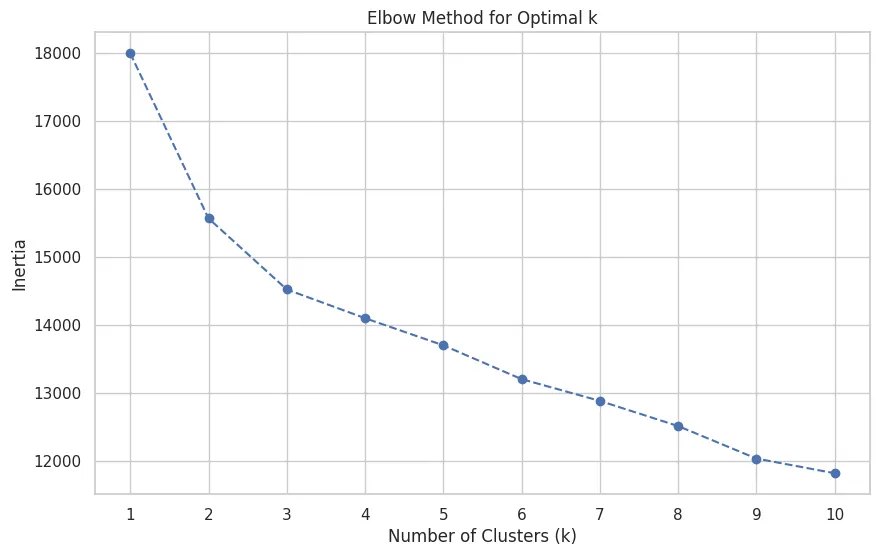
For our example data, three distinct roles looks like the right number.
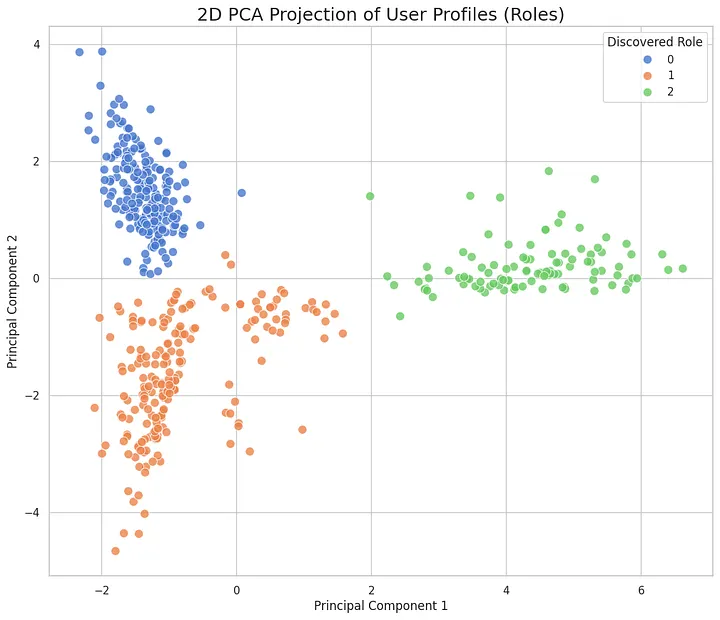
Step 5 & 6: Bringing the Data to Life with Personas & Avatars
This is the final, and most powerful, step. We take the purely quantitative data from each role cluster and feed it back to Gemini. The AI analyzes the dominant jobs and behaviors for each role and generates a complete persona, including a description, key behaviors, primary goals, and potential pain points. To make it even more tangible, we can then generate prompts to create a unique visual avatar for each persona, giving a face to the data.
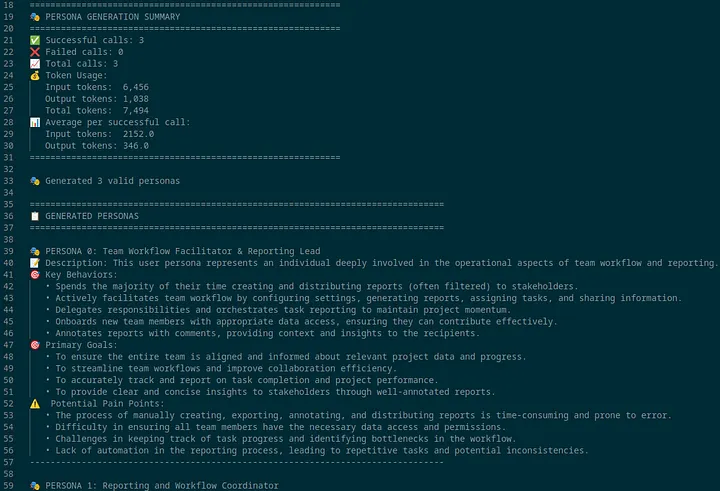
The "So What?" for Your B2B SaaS
This is more than just a clever data science project. This automated, data-driven approach has a direct impact on your go-to-market and customer success efforts.
- Smarter, Proactive Onboarding: Imagine a new user signs up. After their first couple of sessions, the system sees their behavior starting to align strongly with the "Analyst" role. It's not a final verdict, but it's a powerful early signal. Instead of waiting for them to find the right features, you can proactively surface the dashboard and reporting tools they're most likely to value. This isn't about locking them into a path, but about making their initial experience more relevant and accelerating their time-to-value.
- Increased Stickiness & Expansion Revenue: This is huge for customer success. By analyzing an account's role distribution, you can spot "role gaps." See a team with lots of "Creators" but no "Managers"? That might be a signal that they need to add a team lead to their account, a perfect opportunity for an expansion conversation. See an account with roles that aren't using a key feature? You can trigger a targeted campaign to show them how it helps them get their specific jobs done.
- Powering Agentic GTM Workflows: For more AI-native companies, this is the foundation for an agentic or AI-powered GTM. You can build automated systems that use these discovered roles to proactively engage users, suggest next steps, and identify expansion opportunities without manual intervention. It’s about letting the data drive the entire customer journey.
Concrete example: I used the JSON output from my Jupyter notebook and requested Gemini AI to generate a HTML+CSS dashboard visualizing the personas. Here is a screenshot of the end result:
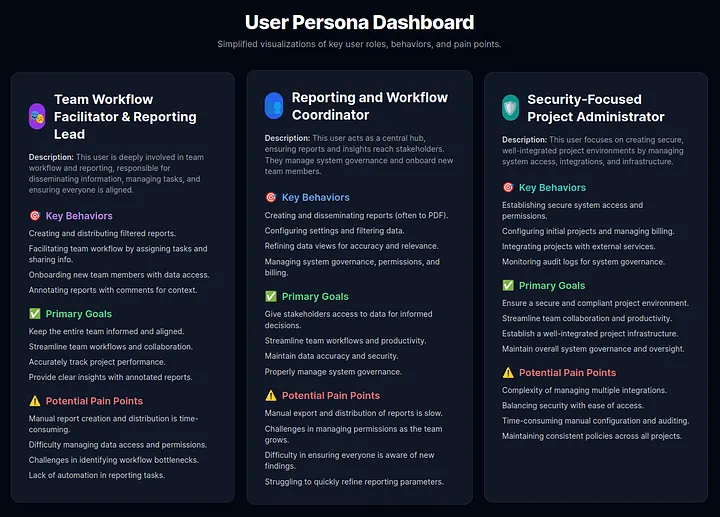
From Assumption to Understanding
Relying on self-reported job titles is building your growth strategy on a foundation of sand. By analyzing what users do, we can move from assumption to a genuine, data-driven understanding of our customers. This allows us to serve them better, build a stickier product, and grow more efficiently.
If you're a fellow founder or leading a growth team, I hope this gives you some ideas. The entire process is repeatable and can be fully automated to provide a constant, evolving picture of who your users truly are.
Can these roles evolve over time, and how do I track that?
Yes, user roles can evolve as products change or users adopt new features. The role discovery process can be run periodically to refresh personas. Tracking the distribution of roles within accounts and observing shifts in individual user behavioral fingerprints can help you identify evolving user needs and adapt your GTM strategies.
Further Reading
- Behavioral Segmentation: Benefits, Types, and Real-World Examples by Amplitude, for strategies on grouping users by their actions.
Links to the Jupyter Notebook
To show how this all comes together, I’ve put the code for this entire process into a Jupyter notebook.
Github Link: https://github.com/ArvoanDev/user-job-and-role-mining
Google Colab Link: https://colab.research.google.com/github/ArvoanDev/user-job-and-role-mining/blob/main/behavioral-role-discovery.ipynb